
The advancements in Large Language Models (LLMs) have revolutionized the way we interact with conversational platforms like ChatGPT. These models, particularly the GPT-4 model, have captivated users with their ability to comprehend text prompts and craft suitable responses in diverse languages. A recent study conducted by researchers at UC San Diego delved into the realm of LLM proficiency through the lens of a Turing test, a method devised to evaluate a machine’s demonstration of human-like intelligence. The preliminary findings of the study imply that distinguishing between the text generated by the GPT-4 model and that produced by a human agent is a formidable challenge.
The research team led by Cameron Jones embarked on an exploratory investigation to determine the degree to which GPT-4 can pass as a human counterpart in conversational interactions. The initial study hinted that in approximately 50% of the cases, participants perceived GPT-4 as human. However, recognizing the need for a more controlled experimental setup, the team proceeded with a second round of experiments to refine their conclusions. This meticulous approach underscores the commitment of the researchers to unravel the nuances of LLM-human interaction dynamics.
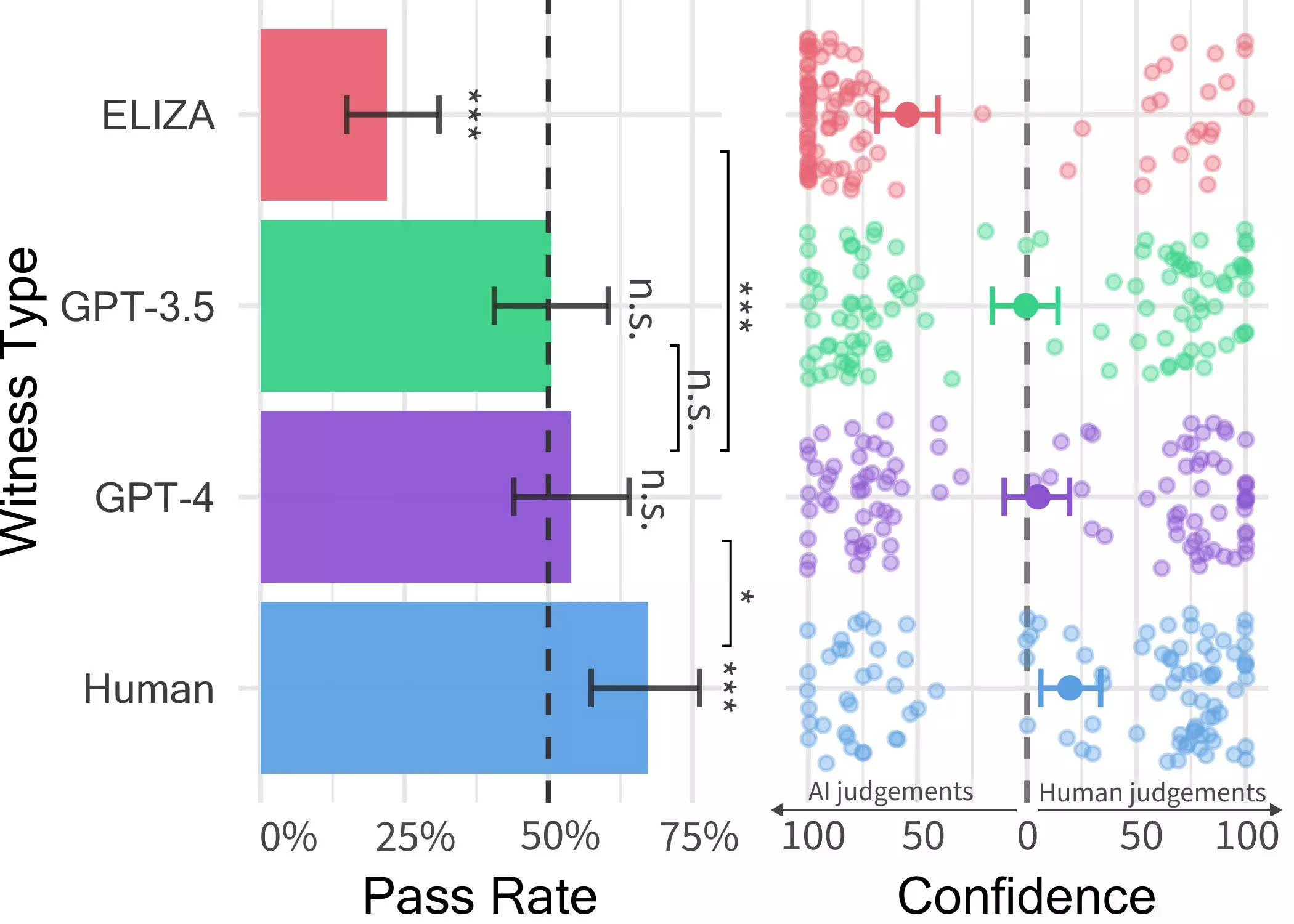
The subsequent experiments orchestrated by Jones and his collaborators introduced a sophisticated two-player game scenario wherein a human interrogator engages with a “witness,” either human or AI, to discern the true identity of the interaction partner. The participants were granted the liberty to engage in open-ended dialogues, presenting a challenging milieu for differentiating between human and machine responses. The utilization of three distinct LLMs, including GPT-4, GPT 3.5, and ELIZA, paved the way for a comprehensive assessment of AI conversational capabilities.
Astoundingly, the findings unveiled that while discerning ELIZA and GPT 3.5 as AI entities posed fewer challenges for the participants, identifying GPT-4 as a machine proved to be as perplexing as a random guess. This revelation underscores the remarkable sophistication of GPT-4 in emulating human conversational patterns, blurring the boundaries between human and AI interactions. The implications of this phenomenon extend beyond mere scientific curiosity, hinting at the profound impact of AI integration in diverse domains such as customer service and information dissemination.
As the boundaries between human and machine interactions continue to blur, the need for stringent evaluation methods to discern AI entities becomes increasingly pressing. The results of the Turing test orchestrated by Jones and Bergen posit a future where individuals might grapple with heightened uncertainty regarding the authenticity of their online conversational partners. The researchers’ forthcoming endeavors, including the proposed three-person game scenario, hold the promise of unveiling groundbreaking insights into the intricate realm of human-AI interaction. Through these endeavors, the researchers aim to shed light on the evolving landscape of conversational AI and its implications for society at large.
Leave a Reply