
Large language models (LLMs) have gained significant popularity in various applications due to their ability to process and generate texts in human languages. However, a recent study by researchers at DeepMind highlights the issue of hallucinations, where LLMs generate nonsensical or inaccurate responses. In response to this challenge, the team proposed a new method to help LLMs identify instances where they should refrain from responding, potentially improving the reliability of these models.
The proposed method involves LLMs evaluating their own responses to determine their similarity and use conformal prediction techniques to develop an abstention procedure. By self-evaluating the responses, the LLMs can potentially identify instances where their answers may be hallucinations. This approach aims to provide rigorous theoretical guarantees on the hallucination rate, ultimately improving the overall performance of LLMs in producing accurate and coherent responses.
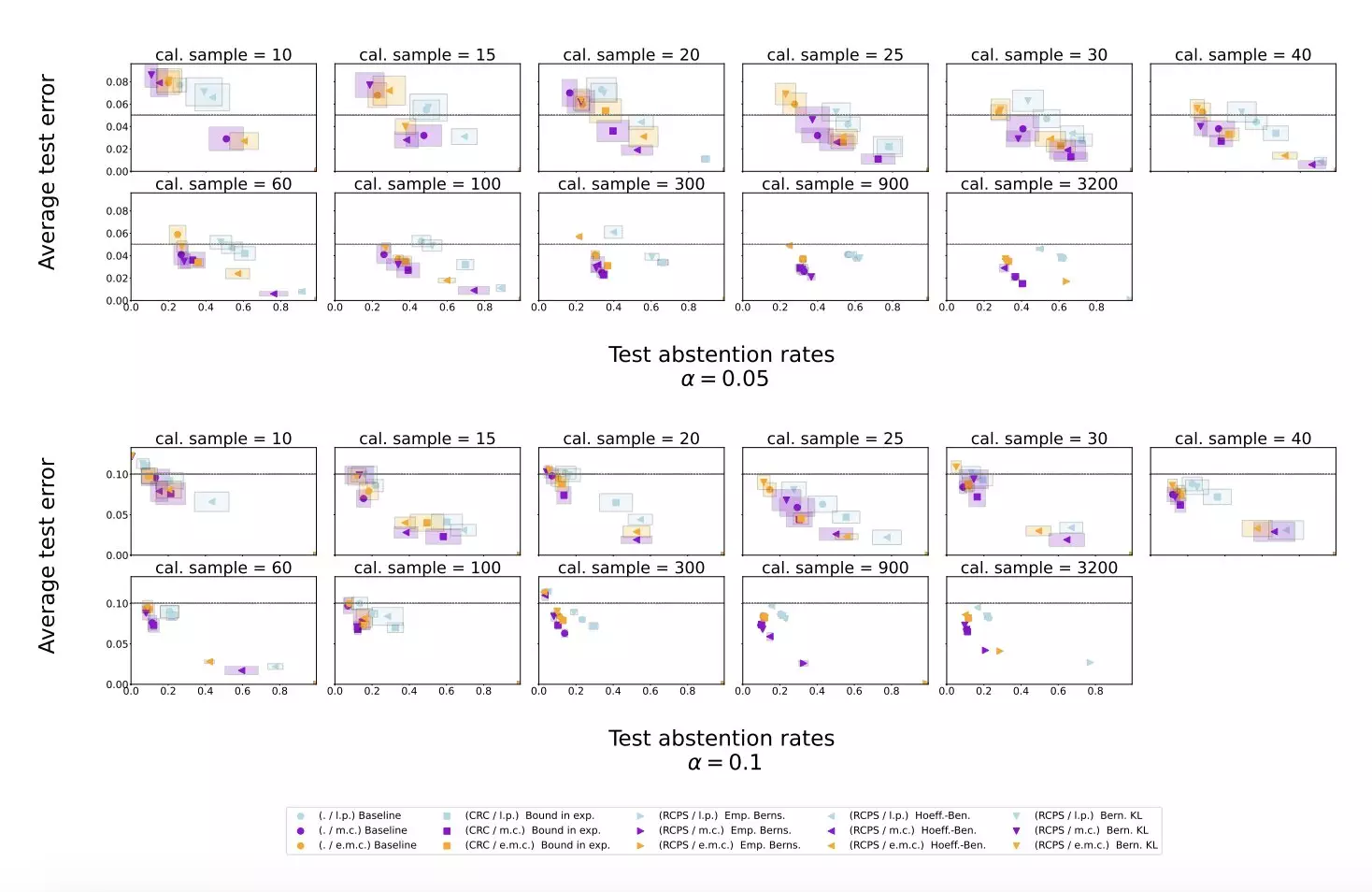
The researchers conducted experiments using publicly available datasets, including Temporal Sequences and TriviaQA, to evaluate the effectiveness of their proposed method. They applied the approach to Gemini Pro, an LLM developed at Google, and compared the results against baseline scoring procedures using log-probability scores. The study found that the conformal abstention method reliably bounded the hallucination rate while maintaining a less conservative abstention rate on datasets with varying response lengths.
The results of the experiments suggest that the conformal calibration and similarity scoring procedure can effectively mitigate LLM hallucinations, allowing the model to abstain from answering when necessary. The study also highlighted that the newly proposed approach outperformed simple baseline scoring procedures. These findings have important implications for improving the reliability of LLMs and preventing them from generating inaccurate or nonsensical responses, ultimately advancing the use of these models in various professional settings.
The study by DeepMind provides valuable insights into addressing the challenge of hallucinations in LLMs, offering a promising method to enhance the performance and reliability of these models. Future research in this area could further explore different approaches to mitigate hallucinations and improve the overall quality of LLM-generated responses. By leveraging advanced techniques and methods, researchers can continue to enhance the capabilities of LLMs and promote their widespread use in diverse domains.
The study by DeepMind represents a significant step in addressing the issue of hallucinations in LLMs. The proposed method shows promise in improving the reliability and accuracy of these models, offering a potential solution to the challenge of generating nonsensical or incorrect responses. By continuing to innovate and develop new approaches, researchers can contribute to the advancement of LLM technology and unlock its full potential in various applications.
Leave a Reply